1. scrapy
[TOC]
- 一些小知识点
- scrapy命令
- 相关类说明
- 数据提取
- item封装数据
- pipeline
- extension
- 模拟登陆
- 数据存储
- 网络代理
- 中间件
- settings
- 分布式爬取
- scrapy使用注释进行调试
- 爬虫部署
- telnet
1.1. 一些小知识点
Scrapy不是一个函数功能库,而是一个爬虫框架。爬虫框架是实现爬虫功能的一个软件结构和功能组件集合。 爬虫框架是一个半成品,需要用户实现部分代码。
scrapy是基于事件的,能在打开上千个链接的同时(并行运行多个请求),通过平稳的操作拆分吞吐量的延迟。
从输出日志出查看爬虫运行过程:
准备启动爬虫 -> 加载setting -> 启动extension -> 启动下载中间件 -> 启动爬虫中间件 -> 启动pipeline -> 爬虫已经启动(spider_opened信号) -> 爬取信息 -> 爬取完成,开始关闭爬虫 -> 显示统计信息 -> 爬虫关闭
日志等级:DEBUG、INFO、WARNING、ERROR、CRITICAL、SILENT(不记录任何日志)
scrapy框架结构:
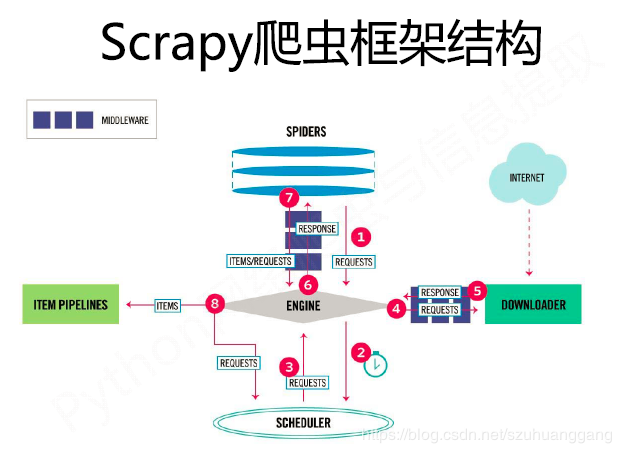
item pipeline后面可以接exporter(一种extension),将item以某种数据格式写入文件。
需要自己编写的:spider、pipeline、settings、middleware(根据需要)。
1.2. scrapy命令
1.2.1. 查看scrapy相关信息
安装scrapy后,查看版本号:
#!/bin/python3
import scrapy
scrapy.version_info
可以使用如下命令进行命令查看:
scrapy -h
scrapy <command> -h
scrapy <command> [options] [args]
1.2.2. 创建爬虫
scrapy genspider [mySpider] [domain]
可以使用参数 --template=TEMPLATE, -t TEMPLATE 指定创建爬虫使用的模板文件。
1.2.3. 启动爬虫
scrapy crawl [spider_name] # spider_name是某个py文件的名字
1.2.4. 为爬虫添加参数
运行爬虫时,可以使用-a添加参数。传进去的都是字符串。如下所示:
scrapy crawl [mySpider] -a x=123 -a y=hg
可以使用以下方法获取:
# 在mySpider类中
x = getattr(self, 'x', 'default')
x = self.x # 如果没有传x参数,该方法或出错
1.2.5. 为项目添加参数
scrapy crawl [mySpider] -s SOME_ARG=xxx
1.2.6. 使用交互式命令进行调试
scrapy shell [url] --nolog # 不要log是为了好看
使用view(response)在浏览器中显示response中的页面(可能和在网上看到的不一样,一个是scrapy爬虫下载的页面,一个是浏览器下载的页面)。
1.2.7. 替换start_urls
指定一个爬虫,爬取给定url的信息(会替换掉爬虫中的 start_urls):
scrapy parse --spider=<xxx> <url>
这是一个相当方便的调试命令。
1.2.8. 启动爬虫,但只爬取部分数据
若是要测试爬虫,而爬虫会爬取上万个页面,可以使用如下参数限定Item或page数量:
scrapy crawl <spider_name> -s CLOSESPIDER_ITEMCOUNT=90
scrapy crawl <spider_name> -s CLOSESPIDER_PAGECOUNT=9
1.2.9. 暂停scrapy爬虫执行
通过增加参数JOBDIR来进行:
在启用爬虫时,即在命令行中加入参数:
scrapy crawl [mySpider] -s JOBDIR=xxx/001在设置文件settings.py添加参数
# settings.py JOBDIR='xxx/001'
在添加完参数后,运行爬虫。在爬虫运行时,按ctrl+c(只按一次)停止爬虫,停止后就会在目录xxx/001下生成相关文件,用来保存相关信息。
注意:这里只能按一次ctrl+c,如果按了两次就表示强制退出了。
生成的xxx/001目录在项目的根目录下(即与scrapy.cfg文件在同一目录)。
下次我们想接着上次爬,就可以用同样的命令启动爬虫,代表我们使用xxx/001文件夹下的状态信息。
1.2.10. 使用脚本启动scrapy爬虫
#!/bin/python3
from scrapy import cmdline
cmdline.execute('scrapy crawl [spider_name]'.split())
1.2.11. 导出数据
-o:指定导出文件路径。可以使用后缀名来指定导出格式。
-t:指定导出数据格式。
scrapy crawl [mySpider] -t csv -o 'export_data/%(name)s_%(time)s.csv'
%(name)s:Spider的名字。
%(time)s:文件创建时间。
1.2.12. 使用模板创建爬虫
使用指定的模板创建爬虫(默认是basic)
scrapy genspider -t basic|crawl|csvfeed|xmlfeed [spider_name] [domain]
1.3. 相关类说明
1.3.1. 1. Request(scrapy.http.request.Request)
Request(url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None)
参数解释:
- callback:Callable类型,Request对象请求的页面下载完成后,由该参数指定的函数解析页面内容。
- meta:元数据字典,dict类型,用于在组件之间传递数据。
- dont_filter:如果对同一url进行多次请求,不对重复请求进行过滤。如果爬取的页面内容会随着时间变化,应该将其置为True。
- errback:Callable类型,请求出现异常或者http错误时的回调函数。
request常用属性:
Response(url, status=200, headers=None, body=b'', flags=None, request=None)
Response只是一个基类,有如下子类:TextResponse、HtmlResponse、XmlResponse。下载器会根据HTTP响应头的Conten-Type创建某个具体的Response对象。
response常用属性:
- url、status、headers(一个类似dict的对象,有get和getlist方法)
- encoding:http响应正文的编码。
- body:http响应正文,bytes类型。
- text:http响应正文,string类型。由body属性通过encoding属性解码得到。
- request:产生该http响应的request对象。
- meta:即response.request.meta。
- selector:用于从Response中提取数据。
response常用方法:
- urljoin(relative_url):将相对链接url构造成绝对链接。
xpath(query)或css(query):实际是response.selector.xxx(query),用于在Response中提取数据。提取出来的是Selector。
re(正则表达式):用于在Response中提取数据。提取出来的是字符串。
1.3.3. 3. 自己编写的Spider(继承scrapy.Spider)
常用属性:
- name:spider的唯一标识,各个spider之间的name不一样。
- start_urls:list,起始爬取页面。调用parse()解析函数。
- logger:自带的日志。
- settings:访问settings。
常用方法:
- parse:页面解析函数,在Request不指定callback参数时,默认使用该方法。
- start_requests:在没设置start_urls时,使用该方法自己爬取起始页(自己构造Request对象)。
1.3.4. 4. 其他
在CrawlSpider(使用 -t crawl 生成)中,使用Rule来跟踪链接,以实现爬虫的双向爬取(对一个页面进行横向和纵向爬取)。
from scrapy.spiders import Rule
rule = Rule(link_extractor, callback = None, cb_kwargs = None, follow = None,
process_links = None, process_request = None )
"""
link_extractor:用于抽取链接
callback:回调函数(即处理response的函数),是一个字符串,而不是方法引用。
cb_kwargs:是一个包含要传递给回调函数的关键字参数的dict。
follow:如果没有设置callback,rule会继续跟踪抽取到的url,并对其抽取链接。如果设置了callback后,仍想跟踪链接,可以将follow设为True,或者在callback中使用yield或return返回它们。
"""
1.4. 数据提取
HTTP常用的文本解析模块:
- BeautifulSoup:API简单易用,但解析速度较慢。
- lxml:由C语言编写的xml解析库,速度快,但API复杂。
scrapy的Selector类,是基于lxml库构建的,并简化了API接口。
Selector内容提取的方法:
- extract()
- re()
- extract_first():SelectorList专有。
- re_first():SelectorList专有。
可以借助谷歌浏览器快速获得某个节点的xpath或css路径:
F12 -> 点击某个节点 -> 单击右键 -> Copy -> Copyselector(css)或者 Copy xpath。
此外,还可以在console中使用表达式 $x('xpath表达式') 来获取相应节点:
$x('//*[@id="content_views"]/pre[15]')
1.4.1. 1. xpath选择器
XPath:XML路径语言(XML Path Language)。
xpath基础语法:
| 表达式 | 描述 |
|---|---|
| / | 用在xpath表达式的最前面,表示文档的根(不是一个节点)。 |
| //xx | 用在xpath表达式的最前面,表示文档中所有的xx节点。 |
| 用在xpath表达式的最前面,表示当前节点的所有子节点。 | |
| yy//xx | yy节点的子孙中,所有的xx节点 |
| . | 当前节点,用于描述相对路径。 |
| .. | 父节点,用于描述相对路径。 |
| xx/* | xx节点的所有子节点 |
| xx/*/yy | 选中xx的孙子节点中,所有的yy节点 |
| xx/@attr | 选中xx节点的attr属性。"a/@href":选中a标签的href属性。 |
| xx/@* | 选中xx节点的所有属性 |
| xx/text() | 选中xx节点中的文本信息 |
| node[谓词] | 用来查找满足谓词条件的节点,如div[@id="xx"],表示id为"xx"的div节点 |
常用谓语函数:
| 谓语 | 含义 |
|---|---|
| 数字>0 | 用来选第几个节点。如xx[num],表示选中第num个节点xx。 |
| xx[last()] | 选中最后一个xx节点。 |
| xx[position()<3] | 选中前2个xx节点。 |
| xx[@attr] | 选中含有attr属性的xx节点。 |
| xx[@attr=”hg“] | 选中含有attr属性为”hg“的xx节点。 |
| xx[contains(@href, ”hg“)] | 选中href属性中包含有"hg"的xx节点。即”hg“是@attr的子串。 'div[contains(text(), ”hg”)]' |
| xx[starts-with(@id, ”hg“)] | 选中xx节点,该节点的attr属性以”hg“开头。 |
| and | 如 ‘div[contains(@id, ”hg”) and contains(@href, ”www”)]’ |
| string(a/b/c) | 返回c节点(只找第一个c节点)下所有子孙节点的文本信息的组合 (即将字符串数组变成一个字符串) |
string详解:
s = Selector()
a = s.xpath( 'string(/html/body/a)' ).extract_first()
b = s.xpath('/html/body/a//text()').extract()
c = ''.join(b)
a==c # True
1.4.2. 2. css选择器
css即层叠样式表。
当使用Selector对象的css方法时,在内部会将css表达式翻译成xpath表达式,然后调用xpath方法。
| 表达式 | 描述 |
|---|---|
| * | 选中所有节点 |
| xx,yy | 选中所有的xx节点和yy节点。 |
| xx yy | 选中xx节点下的所有子孙节点yy。二者之间是空格。 |
| xx>yy | 选中xx节点下的所有子节点yy |
| xx+yy | 选中xx节点的所有兄弟节点yy |
| ._class | 选中class属性为_class的节点。如 'div.info' 表示选中class=info的div节点。 |
| #_id | 选中id为_id的节点。如 'div#main' 表示id=main的div节点。 |
| [attr] | 选中包含属性attr的节点。 |
| [attr=value] | 选中属性attr为value的节点 |
| [attr*=value] | 选中属性attr的值包含value的节点,即value是attr属性的子串。 |
| a[href^="http"] | 选取所有href属性以http开头的a元素。 |
| a[href$=".jpg"] | 选取所有href属性以.jpg结尾的a元素。 |
| xx:nth-child(n) | 选中第n个xx节点 |
| xx:nth-last-child(n) | 选中倒数第n个xx节点 |
| xx:first-child | 第一个xx节点 |
| xx:last-child | 最后一个xx节点 |
| xx:empty | 没有子节点的xx |
| xx::text | xx节点的文本节点 |
| xx::attr(href) | 选取xx节点的href属性 |
| div:not(#main) | 选取所有id不为main的div元素 |
1.4.3. 3. re
使用正则表达式来提取文本。
# 提取所有单词
response.selector.re(r'\w+')
r'.' 是贪婪匹配(最长匹配),r'.\?' 是非贪婪匹配(最短匹配)。
'.' 能匹配除了换行符的任一字符。
1.4.4. 4. LinkExtractor:只提取链接
LinkExtractor是一个专门用来提取链接的类,适用于提取大量链接或提取规则比较复杂的情况。
用来提取页面中的链接。
from scrapy.linkextractors import LinkExtractor # 实际是LxmlLinkExtractor
le = LinkExtractor(allow=(), deny=(), allow_domains=(), deny_domains=(),
restrict_xpaths=(), tags=('a', 'area'), attrs=('href',),
canonicalize=True, unique=True, process_value=None,
deny_extensions=None, restrict_css=())
links = le.extract_links(response) # 提取出来的是scrapy.link.Link的列表。得到的link是绝对地址。
links = [link.url for link in links]# 获取链接
?使用这个提取出的链接在末尾可能有问题,如本来是"baidu.com",结果变成了"baidu.com/"。
参数解释:
- allow:一个正则表达式或一个正则表达式列表。?正则不是完全匹配,是有部分匹配就OK了。
- deny:同allow,只是意思相反。
- allow_domain:一个域名或列表,提取指定域名的link。
- restrict_xpaths:一个xpath表达式或列表。只能提取该表达式选中区域下的link。
- tags:用于提取指定标签中的链接。
- attrs:只能提取tags中的attrs标签。
- process_value:接受一个回调函数,对提取的链接(一个字符串)进行处理。如果丢弃某个链接,返回None。
1.5. item封装数据
item是一个类似dict的对象,支持字典接口。定义如下:
import scrapy
class MyItem(scrapy.Item):
name = scrapy.Field()
age = scrapy.Field()
在对item对象赋值时,如果字段名没有预先定义,将会抛出异常(防止粗心将字段名写错)。
但是,item可以使用fields属性动态添加字段:
item = Item()
item.fields['name'] = Field()
如果想要传递额外信息给处理数据的某个组件,可以使用Field的元数据:
class MyItem(scrapy.Item):
x = scrapy.Field(len=20, serializer=lambda x: x)
> it = MyItem()
> it.fields
Out: {'x': {'len': 20, 'serializer': <function __main__.MyItem.<lambda>>}}
> it.fields['x']
Out: {'len': 20, 'serializer': <function __main__.MyItem.<lambda>>}
> type(it.fields['x'])
Out: scrapy.item.Field
元数据可以用来对Item的某个属性进行限制:如x怎么进行序列化。
item除了记录用户想要的信息外,还可以添加一些额外信息,帮助我们调试爬虫,比如何地(url)、何时(time)、使用那个爬虫(spider)抓取的数据。
1.5.1. ItemLoader
在爬虫中,构造Item除了先生成一个对象,然后填充相应属性外,还可以使用ItemLoader来完成。
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose, Join
l = ItemLoader(item=myItem(), response=response)
# l = ItemLoader(item=myItem(), selector=response.selector)
l.add_xpath('name', '//*[@id="name"][1]/text()', MapCompose(str.strip, str.title),
Join(separator='|'))
# l.add_xpath(self, field_name, xpath, *processors, **kw)
# l.add_css(...)
# l.add_value('url', response.url)
item = l.load_item()
MapCompose可以填入函数链,用于对提取出来的每一个元素进行清洗。
1.6. pipeline
pipeline的作用:
- 清洗数据
- 验证数据的有效性
- 过滤掉重复的数据
- 将数据保存到文件或数据库
pipeline定义:
class MyPipeline(object)
def __init__(self):
# 可选实现,做参数初始化等
pass
def process_item(self, item, spider):
# item是爬取到的数据, spider是爬取到该数据的Spider对象。
if True:
return item
else:
raise scrapy.exceptions.Dropitem()
def open_spider(self, spider):
# 可选实现,当spider被开启时,这个方法被调用。
pass
def close_spider(self, spider):
# 可选实现,当spider被关闭时,这个方法被调用
pass
@classmethod
def from_crawler(cls, crawler):
return cls()
主要方法:
- process_item:主要方法,对item进行处理。如果item不需要继续在流水线上进行处理,可以抛出DropItem异常(scrapy.exceptions.Dropitem),该item就会被抛弃。
- fromcrawler(cls, crawler):通常在该方法中,通过crawler.settings来读取相关配置信息,然后根据配置调用_init方法创建Item Pipeline对象。
- _init_(self):可以用于初始化某些数据。比如创建一个集合,用来保存所有经过该流水线的item,然后用于查重。
过滤重复数据:在初始化时,创建一个set。然后在处理item时判断该项是否在set中。
1.6.1. 1. FilesPipeline
配置:
# settings.py
ITEM_PIPELINES = {'scrapy.pipelines.files.FilesPipeline': 1}
FILES_STORE = '/path/to/valid/dir' # 相对于项目的根目录(scrapy.cfg所在目录)
下载过程:
- 在item中查找"file_urls"字段(是一个列表)。
- 根据"file_urls"字段下载相应的文件。
- 向item添加字段'files',存放下载结果。主要有:
- Path:文件下载到本地的路径(相对于"FILES_STORE"的相对路径)。
- Checksum:文件的校验和。
- url:文件的url地址。
下载的文件名为:
# SHA1_HASH_VALUE为下载文件url的sha1散列值。是为了防止重名文件覆盖。
[FILES_STORE]/full/[SHA1_HASH_VALUE].[format]
重载命名方法:
from urllib.parse import urlparse
import os
class MyPipeline(FilesPipeline):
def file_path(self, request, response=None, info=None):
# 根据request的相关信息,返回一个文件名(字符串)
# 传进来的request可能是一个url
if not isinstance(request, Request):
url = request
else:
url = request.url
path = urlparse(url).path # 得到url中的路径部分(除去域名、参数等)
dir = os.path.dirname(path)
name = os.path.basename(path)
return 'xxx'
1.6.2. 2. ImagesPipeline
ImagesPipeline是FilesPipeline的子类。
使用上大致相似,只是item字段由"file_urls"、"files"变成了"image_urls"、"images"。
配置:
# settings.py
ITEM_PIPELINES = {'scrapy.pipelines.images.ImagesPipeline': 1}
IMAGES_STORE = '/path/to/valid/dir'
# 生成缩略图
THUMBS = {
'small':(50,50),
'big':(270,270),
}
# 过滤掉长宽不符合要求的图片
IMAGES_MIN_WIDTH = 110
IMAGES_MAX_WIDTH = 110
1.7. extension
1.7.1. 1. Exporter
已有实现:
- json
- json lines:jsonlines或jl。
- csv
- xml
- pickle
- marshal
前4种为常用格式,后2中为python特有。
配置:
# 位于scrapy.settings.default_settings模块
FEED_EXPORTERS_BASE = {
'json': 'scrapy.exporters.JsonItemExporter',
# ...
}
# settings.py
FEED_EXPORTERS = {
'myjson': 'MyItemExporter',
}
如果自己实现的话,需要继承BaseItemExporter:
from scrapy.exporters import BaseItemExporter
def MyItemExporter(BaseItemExporter):
def export_item(self, item):
# 负责导出数据
pass
def start_exporting(self):
# 在导出开始时被调用,用于某些初始化工作
pass
def finish_exporting(self):
pass
1.8. 模拟登陆
1.8.1. 1. 构造表单
scrapy提供了一个FormRequest类(Request的子类),用于构造含有表单的请求。
构造FormRequest:
from scrapy.http import FormRequest
fd = {
'username':'xxx',
'password':'xxx',
}
request = FormRequest.from_response(response, formdata=fd) # 隐藏的表单项会自动填充。
1.8.2. 2. 使用Cookie
1.9. 数据存储
主要有SQLite、MySQL、MongoDB、Redis。
1.9.1. 1. SQLite
在python3中:
import sqlite3
conn = sqlite3.connect('example.db')
cur = conn.cursor()
cur.execute('insert into person values(%s,%s)', (name, age))
conn.commit()
conn.close()
1.9.2. 2. mysql
python3有pymysql、mysqlclient包。
在python2中使用MySQLdb访问数据库,在python中使用mysqlclient作为替代,提供几乎完全相同的接口。
import MySQLdb # 在python3中,实际安装的是mysqlclient包
import pymysql
conn = sqlite3.connect(host='localhost', db='example', user='root',
passwd='xxx', charset='utf8')
"""
conn = pymysql.connect(host='localhost', port=3306, db='example',
user='root',passwd='xxx', charset='utf8')
"""
cur = conn.cursor()
cur.execute('[SQL statement]')
conn.commit()
conn.close()
1.9.3. 3. mongodb
mongodb是一个文档数据库,数据以键值对进行存储。
数据组织:库(database) -> 集合(collections) -> 文档(document)
windows上可以使用mongodb的管理软件RoboMongo。
默认情况下,mongodb只允许本机访问。如需远程访问,需修改配置文件:
# mongod.conf
# bindIp: 127.0.0.1
bindIp: 0.0.0.0
如非必要,别远程访问mongodb。
from pymongo import MongoClient
uri = "mongodb://[user]:[passwd]@[localhost]:27017"
client = MongoClient("mongodb://localhost:27017")
db = client['example_db']
db['example_collection'].insert_one({'name':'xx','age':18})
client.close()
1.9.4. 4. Redis
redis是一个基于内存的非关系型数据库。redis以键值对(key-value)存储数据。
默认情况下,redis只能被本机访问,如果需要远程访问,需要对配置文件进行修改:
# /etc/redis.conf
# bind 127.0.0.1
bind 0.0.0.0
# protected-mode yes
protected-mode no
# requirepass foobared
requirepass [my_password]
注:远程访问redis风险极大,请谨慎使用。
键值对中的值主要有5种类型:
- 字符串(string):可以存储字符串、整数、浮点数(数字也是字符串)。
- 哈希(hash):用于存储多个键值对,其中的键值都是字符串。
- 列表(list)
- 集合(set)
- 有序集合(zset)
from redis import StrictRedis
conn = StrictRedis(host='127.0.0.1', port=6379, db=redis_db_index)
conn.hset('person', 'xiaoming', {'name':'xx','age':18})
conn.connection_pool.disconnect()
1.9.5. 5. 异步访问数据库
Twisted提供了以异步方式多线程访问数据库的模块adbapi。使用该模块可以显著提高程序访问数据库的效率。
from twisted.enterprise import adbapi
# adbapi只是提供了一个异步访问数据库的编程框架,内部依旧使用MySQLdb、sqlite3这样的库访问数据库
dbpool = adbapi.ConnectionPool('MySQLdb', host='localhost', database='example',
user='root', passwd='xxx', charset='utf8')
# 该函数将被异步调用。tx是一个Transaction对象,其接口与cursor类似。在该方法执行完后,会自动commit
def insert_db(tx, item):
name, age = item
tx.execute('insert into person values(%s,%s)', (name, age))
dbpool.runInteraction(insert_db, (name, age))
dpool.close()
1.10. 网络代理
爬虫使用代理的原因:
- 直接爬取速度太慢,使用代理提高爬取速度。
- 网站对用户进行访问限速,爬取过快会封ip。
- 某些网站被墙,不能直接访问。
1.11. 中间件
中间件:对经过中间件的对象进行修改、丢弃、新增操作。
scrapy中间件中,处理request请求的函数,返回不同的值:
None:将请求交给后续的中间件进行处理。
Request:将请求交给调度器重新调度,并终止后续中间件的执行;
Response:终止后续中间件及下载器的执行,直接将Response交给引擎。
Exception:抛出异常。
scrapy中间件中,处理response响应的函数,返回不同的值:
Request:终止后续中间件的执行,将请求重新交给调度器进行调度。
Response:继续执行后续的中间件。
Exception:抛出异常。
1.11.1. 1. 下载中间件
用途:
- 代理中间件
- User-Agent中间件
- Cookies中间件
- 集成selenium的中间件
- 对请求失败进行重试的中间件
- 对请求异常进行处理的中间件
1.1 Cookie中间件
scrapy.http.cookies.CookieJar # 1
http.cookiejar.CookieJar # 2
http.cookiejar.Cookie # 3
1是对2的封装,使用1.jar就可以的到2。而2是由多个Cookie(3)组成的,可以使用循环遍历Cookie。
Cookie有多个属性,如name、value、domain、path、expires等。
Request通过meta属性中的'cookiejar'指定使用CookiesMiddleware中的哪一个CookieJar。
1.2 HTTP代理中间件
HttpProxyMiddleware是默认开启的,它会从系统环境变量中搜索当前系统代理(名字格式为xxx_proxy的环境变量),作为Scrapy爬虫的代理。
scrapy中设置代理,就是将代理服务器的 url 填写到 request.meta['proxy'] 中。
HttpProxyMiddleware对于一个协议(如http),只能设置一个代理。为了使用多个代理,可以将代理服务器的 url 添加进request请求的meta['proxy'] 中,从而实现多个代理。这样做,如果代理存在验证环节的话,还需要自己手动将 "user:passwd" 进行编码,放入请求头的 Proxy-Authorization 中。可以参考源码的实现。
假设我们在linux上搭建好了代理服务器,设置环境变量:
# 这样只是临时设置,在shell关闭时失效。
export http_proxy="http://123.123.123.123:1234" # http代理
export https_proxy="http://123.123.123.123:12345" # https代理
# 带验证
export http_proxy="http://user:passwd@123.123.123.123:1234" # http代理
export https_proxy="http://user:passwd@123.123.123.123:12345" # https代理
可以使用http://httpbin.org/提供的服务来窥视我们发送的请求,如源ip地址、请求头部、Cookie等信息。可以用来验证代理是否正常工作。
访问 http://httpbin.org/ip ,将返回一个包含请求源IP地址信息的json串。
获取免费代理的网站:
- http://proxy-list.org/ (国外)
- https://free-proxy-list.org/ (国外)
- http://www.xicidaili.com
- http://www.proxy360.cn
- http://www.kuaidaili.com
1.11.2. 2. 爬虫中间件
作用:
- 处理爬虫本身的异常
1.12. settings
官方文档中scrapy中settings参数有四个级别:
- 命令行选项(Command line Options)(最高优先级):
scrapy crawl somespider -s LOG_FILE=t.log - 项目设定模块(Project settings module):custom_settings
- 命令默认设定模块(Default settings per-command):项目目录下的settings文件。
- 全局默认设定(Default global settings) (最低优先级)
1.12.1. custom_settings
custom_settings可以理解为spider的个性设置,通常我们在一个项目目录下会有很多个spider,但是只有一个settings.py全局配置文件,为了让不同的spider应用不同的设置,我们可以在spider代码中加入custom_settings设置。
例如:
spiders/somespider.py
from ..custom_settings import *
class Spider1(CrawlSpider):
name = "spider1"
custom_settings = custom_settings_for_spider1
pass
custom_settings.py
custom_settings_for_spider1 = {
'LOG_FILE': 'spider1.log',
'CONCURRENT_REQUESTS': 100,
'DOWNLOADER_MIDDLEWARES': {
'spider.middleware_for_spider1.Middleware': 667,
},
'ITEM_PIPELINES': {
'spider.mysql_pipeline_for_spider1.Pipeline': 400,
},
}
在spider里有两个蜘蛛spider1、spider2里,我们引入了来自custom_settings的配置变量custom_settings_for_spider1、custom_settings_for_spider2,通过这些变量,我们分别对两个爬虫的log文件、并发数、应用的中间件和管道文件进行了设置。
custom_settings的优先级在命令行以下,比settings.py要高。
1.12.2. settings的使用技巧
在这简单说说我在工作中对于不同类型settings的使用技巧吧。
1.首先是settings.py文件,在一个scrapy项目中,一些通用的设置,比如请求头、代理入口、数据库连接等等,都可以统一写在settings.py中。
2.其次是custom_settings,在scrapy项目中单独建立一个custom_settings.py文件,依据不同spider所需要的设置,比如某站点A可能反爬严,我并发设置短点,站点B没反爬,我并发设置高点;又或者A用了中间件MA,B用了中间件MB等,我在custom_settings.py文件中分别给予设置。
3.最后是命令行。例如我要每个进程的日志分别查看,或者追踪每个进程的爬取速度等,这用命令行参数就比较合适。例如:
from scrapy import cmdline
cmdline.execute('scrapy crawl spider1 -s LOG_FILE=p1.log -s PROCESS_NAME=1'.split())
1.13. 分布式爬取
第三方库 scrapy-redis 为scrapy框架扩展了分布式爬取的功能,使用redis + scrapy-redis 实现。
分布式爬虫框架需解决:
- 分配爬取任务:为每个爬虫分配不重复的爬取任务。
- 汇总爬取数据:将所有爬虫爬取到的数据汇总到一处。
scrapy-redis 让所有爬虫共享一个存在于redis中的请求队列(代替原先各个爬虫的独立请求队列)。
scrapy-redis 实现了以下组件:
- 基于redis的请求队列:优先队列(默认)、FIFO、LIFO
- 基于redis的请求去重过滤器:过滤掉重复请求。
- 基于以上两个组件的调度器。
分布式爬取使用:
修改原scrapy项目的爬虫文件:
- 使爬虫继承 "scrapy_redis.spiders.RedisSpider",而不是原来的 "scrapy.Spider"
- 注释掉 start_urls。
修改配置文件:
# settings.py REDIS_URL = 'redis://1.2.3.4:6379' # 可远程访问 SCHEDULER = 'scrapy_redis.scheduler.Scheduler' DUPEFILTER_CALSS = 'scrapy_redis.dupefilter.RFPDupeFilter' # 去重 ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline':300 } # 爬虫停止后,是否清除redis中的请求队列、去重集合。默认为False,即清除。 SCHEDULER_PERSIST = False """ REDIS_START_URLS_KEYS = '<spider_name>:start_urls' # redis的键,从该队列中获取初始爬取链接 存储爬取的item键:'<spider_name>:items',是一个list 存储去重集合的键: '<spider_name>:dupefilter',是一个set """将源文件部署到若干台机器上,并启动爬虫。此时请求队列是空的,爬虫都处于等待状态。
打开redis,放入初始链接:
lpush <spider_name>:start_urls 'https://www.baidu.com'爬虫开始爬取数据。
1.14. scrapy使用注释进行调试
contract有点像为爬虫设计的单元测试,可以让你快速知道哪里有运行异常。
主要实现在 scrapy.contracts.deafult.py中。
def parse(self, response):
""" This function parses a property page.
@url http://xx.com/xx.html
@returns items 1
@scrapes title price description address image_urls
@scrapes url project spider server date
"""
pass
上述代码的含义是:检查该url,并找到列出字段中有值的一个item。
测试某个爬虫(根据上面的注释):
scrapy check <spider_name>
1.15. 爬虫部署
Scrapyd是官方开发的,用于部署、运行和管理scrapy的工具。scrapyd没有权限管理(即不能设置密码)。
首先先将scrapyd安装在云服务器上:
pip install scrapyd
pip install scrapyd-client
配置文件:
# /etc/scrapyd/scrapyd.conf
[scrapyd]
bind_address = [云服务器的外网ip]
启动,直接键入以下命令:
scrapyd
就可以进行访问了:http://[云服务器的外网ip]:6800。
部署爬虫:
打开项目的scrapy.cfg文件,将第10行的url改为上面的url。
然后键入以下命令进行部署:
scrapyd-deploy # 在项目根目录下打开命令行
启动爬虫:
curl http://[host]:6800/schedule.json -d project=[project_name] -d spider=[spider_name]
启动后,就可以在网页上查看相关情况了。
结束爬虫:
curl http://[host]:6800/cancel.json -d project=[project_name] -d spider=[spider_job_id]
1.16. telnet
telnet 监测爬虫运行,并且可以运行python代码
连接telnet:telnet localhost 6023(or 6024)
常用命令:
est ( ): 查看爬虫引擎各组件的运行状态p(stats.get_stats()):查看爬虫已经运行的各项指标
:coffee: :zapple